End Of Magic Era Machine Translation
Machine translation (MT), the process of automatically converting text from one language to another, has undergone a dramatic transformation in recent years. This evolution has been so profound that it’s often described as the “end of the magic era” in MT. To understand this shift, we need to consider the history of MT, the challenges it faced, and the breakthroughs that have led to its current state.
A Brief History of Machine Translation
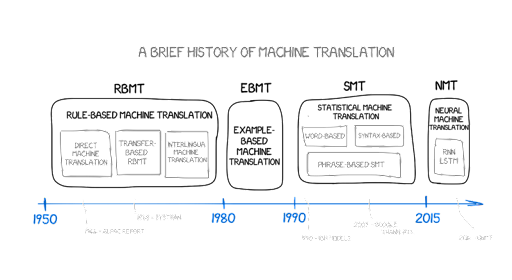
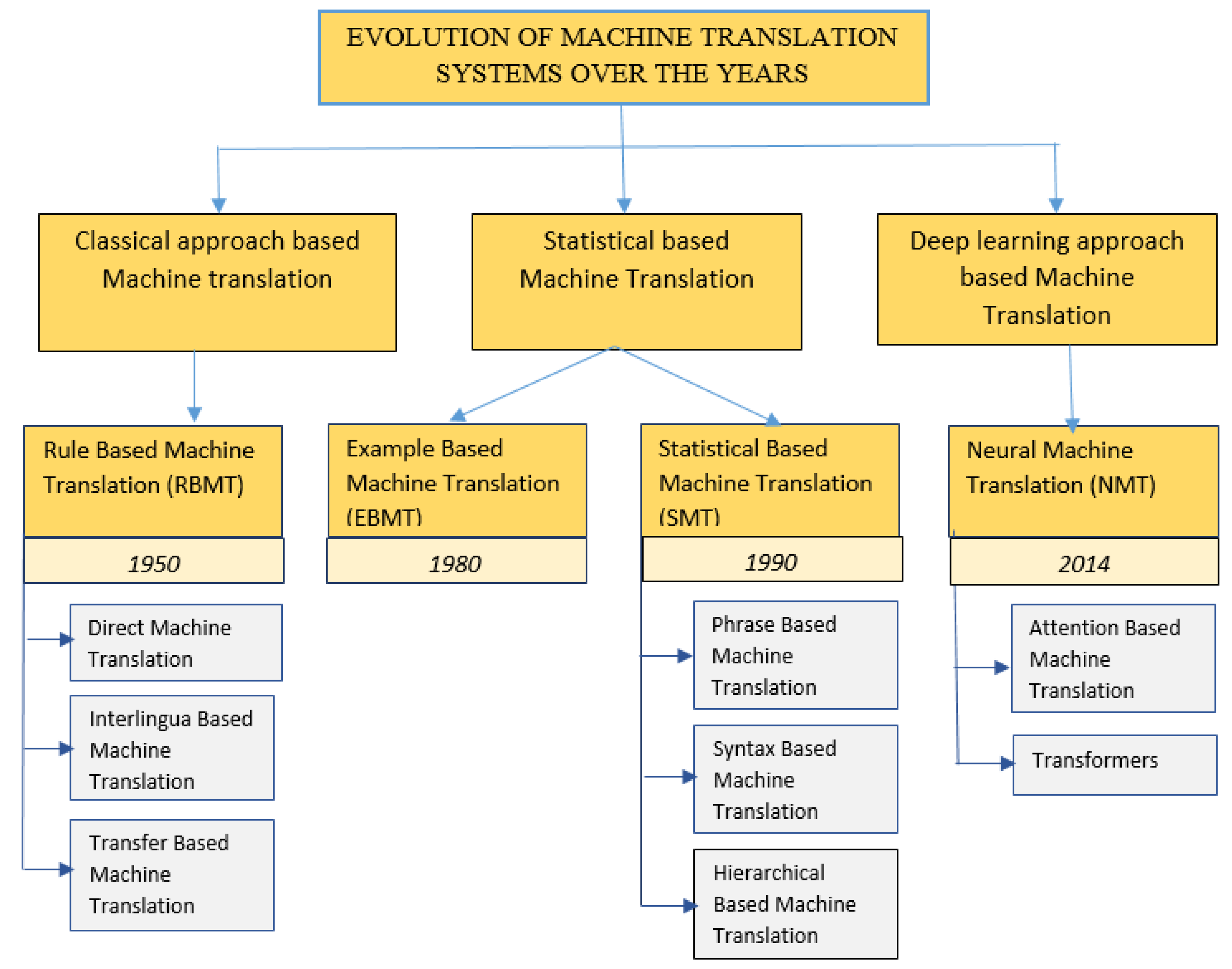
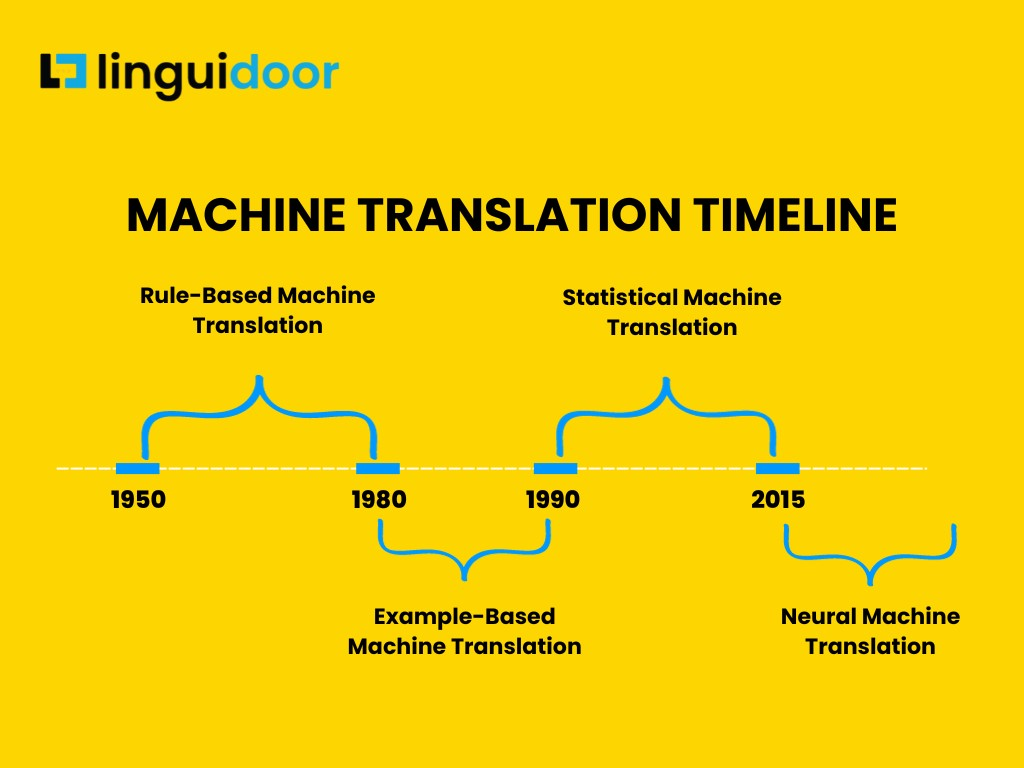
The dream of automated translation dates back to the mid-20th century, fueled by the Cold War and the need for rapid access to information in multiple languages. Early approaches, often called rule-based machine translation (RBMT), relied on explicitly programmed grammatical rules and dictionaries. Linguists meticulously crafted these rules, defining how sentences should be parsed and transformed from the source language to the target language.
RBMT systems, while conceptually straightforward, proved to be incredibly complex and brittle. Languages are full of ambiguity, idiomatic expressions, and exceptions to rules. Maintaining and updating these rule sets was a monumental task, requiring extensive linguistic expertise and constant adjustments. The systems often struggled with even moderately complex sentences, producing translations that were accurate only in limited domains.
Must Read
A significant challenge was disambiguation. For example, the word “bank” can refer to a financial institution or the side of a river. Rule-based systems had difficulty determining the correct meaning based on context, leading to nonsensical translations. Furthermore, RBMT systems were typically language-pair specific. Developing a new translation system for a different language pair required building a completely new set of rules and dictionaries from scratch.
In the late 1980s and 1990s, statistical machine translation (SMT) emerged as an alternative. SMT systems moved away from handcrafted rules and instead relied on large parallel corpora – collections of texts and their translations. These systems statistically analyzed the relationships between words and phrases in the source and target languages to learn how to translate.
SMT used probabilistic models to determine the most likely translation of a given sentence. The quality of the translation depended heavily on the size and quality of the parallel corpora. While SMT systems often outperformed RBMT systems in terms of fluency and naturalness, they still had limitations. They struggled with long-range dependencies and lacked a deep understanding of meaning. SMT systems also tended to be data-hungry, requiring massive amounts of parallel data to achieve good performance, which was not always available for less common language pairs.

The Rise of Neural Machine Translation
The “end of the magic era” truly began with the advent of neural machine translation (NMT) in the mid-2010s. NMT leverages deep learning techniques, specifically recurrent neural networks (RNNs) and later, transformers, to learn the mapping between languages. These neural networks are trained on massive amounts of data, just like SMT, but they learn more complex and nuanced relationships than statistical models could capture.
Unlike RBMT, NMT doesn’t require explicit rules. And unlike SMT, NMT doesn't rely on word-to-word or phrase-to-phrase alignment. NMT systems learn to encode the meaning of the entire source sentence into a vector representation, which is then decoded into the target language. This allows NMT to handle long-range dependencies and contextual information more effectively.
Early NMT models used RNNs with attention mechanisms. The attention mechanism allowed the decoder to focus on the relevant parts of the source sentence when generating each word in the target sentence. This significantly improved the fluency and accuracy of translations. However, RNNs have limitations in processing long sequences due to the vanishing gradient problem.
The introduction of the transformer architecture in 2017 revolutionized NMT. Transformers rely on self-attention mechanisms, which allow each word in the sentence to directly attend to all other words, regardless of their distance. This eliminates the need for sequential processing, making transformers much more efficient and scalable than RNNs. Transformer-based models, such as Google Translate's Transformer model, have achieved state-of-the-art results on various MT benchmarks.
Key Advantages of Neural Machine Translation
NMT offers several significant advantages over previous approaches:
- Improved Fluency and Accuracy: NMT systems produce more natural-sounding and accurate translations than RBMT and SMT systems.
- End-to-End Learning: NMT systems learn directly from raw data, without the need for handcrafted features or rules.
- Contextual Understanding: NMT systems can better capture the context of a sentence and resolve ambiguities.
- Multilingual Capabilities: NMT models can be trained on multiple language pairs simultaneously, allowing for transfer learning and improved performance on low-resource languages.
- Handling of Idioms and Colloquialisms: NMT models are better at translating idioms and colloquial expressions.
The Ongoing Evolution of Machine Translation
While NMT has achieved remarkable progress, the field continues to evolve. Current research focuses on several key areas:
- Low-Resource Machine Translation: Developing methods to train NMT models with limited amounts of parallel data. This includes techniques like back-translation, which uses a model trained on high-resource languages to generate synthetic parallel data for low-resource languages.
- Domain Adaptation: Adapting NMT models to specific domains, such as medical or legal texts. This involves fine-tuning models on domain-specific data to improve performance.
- Multilingual Machine Translation: Building models that can translate between multiple languages simultaneously. This reduces the number of models required and allows for transfer learning between languages.
- Explainable Machine Translation: Developing methods to understand why NMT models make certain translation decisions. This is important for debugging models and building trust in their outputs.
- Incorporating Knowledge: Integrating external knowledge sources, such as knowledge graphs, into NMT models. This can improve the accuracy and coherence of translations.
Furthermore, research is actively being conducted on areas like: handling code-switching (instances where multiple languages are used within a single sentence), improving the robustness of NMT models to noisy or adversarial inputs, and developing more efficient and scalable training methods.
The "End of Magic": What It Really Means
The phrase "end of the magic era" signifies that machine translation is no longer perceived as an unattainable or mysterious goal. It reflects a shift from relying on intricate, handcrafted rules (which often felt like "magic" when they worked, and more like frustration when they didn't) to leveraging data-driven, statistical approaches powered by deep learning. While there's still plenty of room for improvement, the field has matured significantly. We now have systems that can produce translations of remarkable quality, and the development process is less about manually crafting rules and more about training and refining complex neural networks.
The magic hasn't disappeared entirely, of course. The inner workings of deep learning models remain somewhat opaque, and the ability of these models to learn complex patterns from data can still feel awe-inspiring. However, the key difference is that the process is now more systematic, data-driven, and reproducible. Researchers and developers can iterate on models, analyze their performance, and identify areas for improvement in a more principled way.
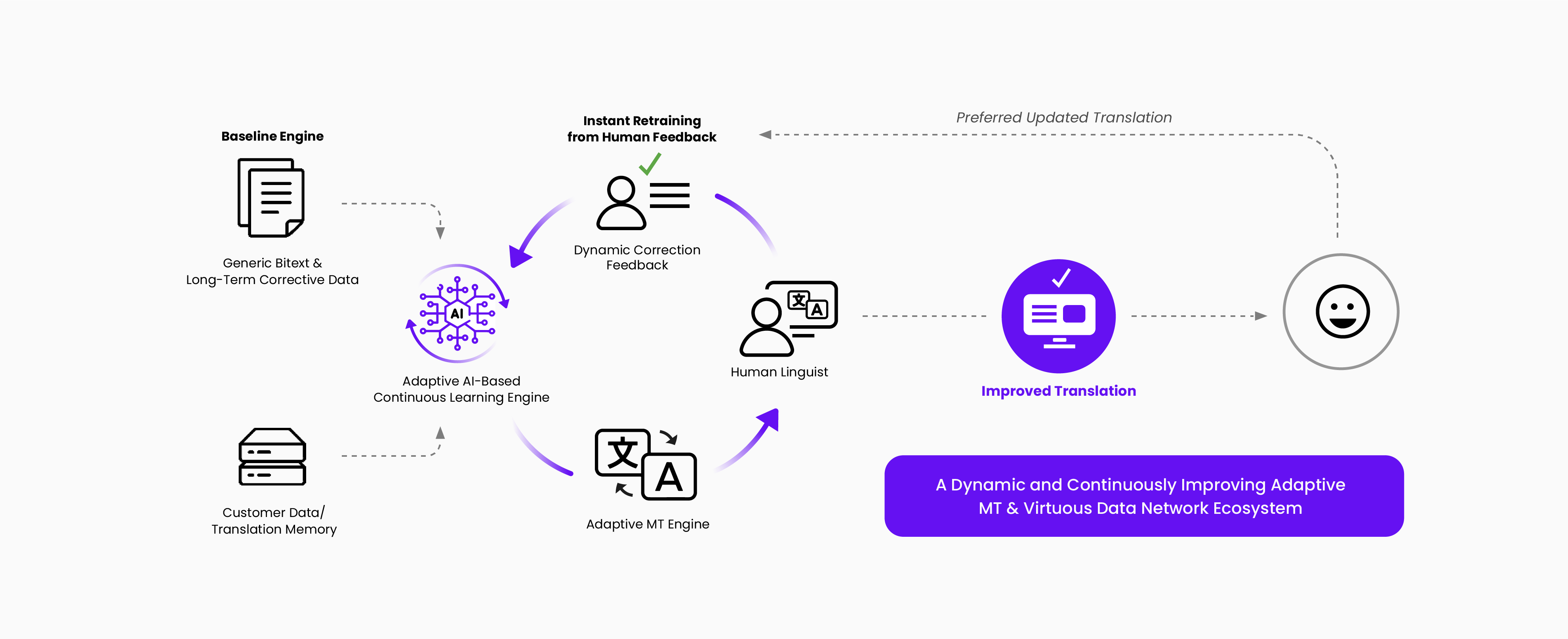
However, the availability of high-quality MT systems should not make us complacent. There are inherent biases in training data that can get reflected into translation result. Work on ethics and fairness is an important ongoing effort.
Why This Matters
The advancements in machine translation have profound implications for global communication, accessibility, and economic development. High-quality machine translation enables:
- Breaking Down Language Barriers: Facilitating communication and collaboration between people who speak different languages.
- Access to Information: Making information available to a wider audience, regardless of their language proficiency.
- Globalization: Supporting international trade, travel, and cultural exchange.
- Education and Research: Providing access to educational resources and research findings in multiple languages.
- Business and Commerce: Automating translation tasks, reducing costs, and improving efficiency.
The ongoing evolution of machine translation continues to shape the way we interact with the world, making information more accessible and fostering greater understanding between cultures.